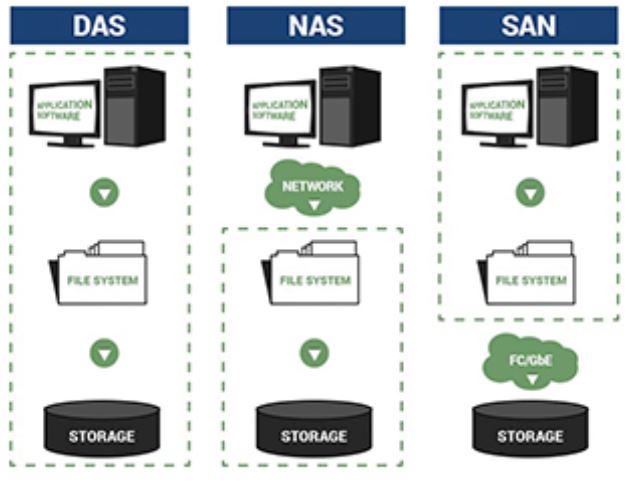
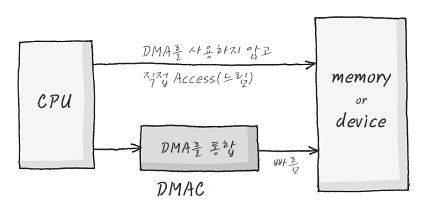
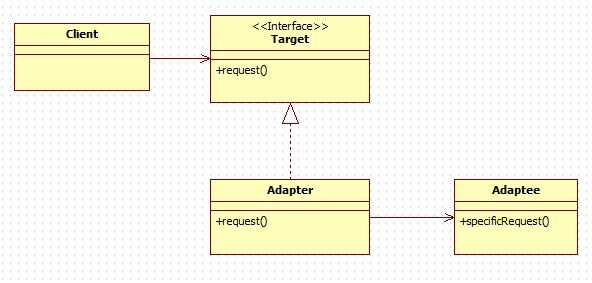
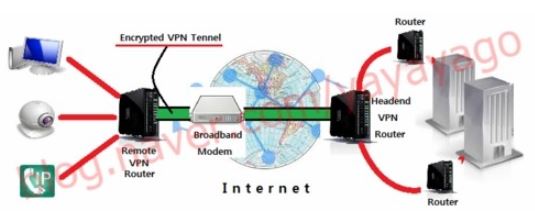
[운영체제] 세그먼트
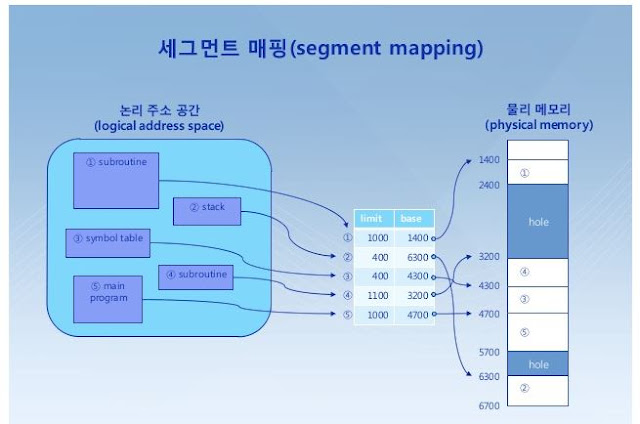
[운영체제] 세그먼트 메모리 세그먼트 메모리 보호를 수행하는 가장 일반적인 방법 가운데 하나이다. 또 페이징이 있다. 세그먼트를 사용하는 컴퓨터 시스템에서 메모리 위치를 참조하는 명령어는 피연산자와 세그먼트와 그 세그먼트안의 오프셋을 증명하는 값을 포함하고 있다. 프로그램 메모리 세그먼트 컴파일러에 의해 자동적으로 프로그램이 프로세스에 올라 갈 때 세그먼트가 나뉘게 되는데, 주로 코드 영역, 데이터 영역, 스택(Stack)영역으로 나뉘게 된다. 데이터 메모리는 크게 코드 세그먼트 스택 세그먼트 데이터 세그먼트 힙 세그먼트 로 구분된다. 코드 세그먼트 소스파일의 코드가 할당되어 잡히는 메모리 영역이다. 이 부분에 변화가 있어선 안되기 때문에 기본적으로 쓰기가 금지 되어 있다. 스택 세그먼트 지역변수가 할당된다. 스택 구조로 쌓아 올려짐으로써 재귀호출이 가능해진다. 이 곳에서 호출된 변수들은 임시적인 성격을 가지게 되는데 이유는 스택 세그먼트에서 호출된 변수는 호출된 지역(함수)에서만 사용이 가능하기 때문이다. (이는 코딩을 할 때 같은 이름의 변수를 서로 다른 함수에서 따로 사용할 수 있는 이유와 같다.) 따라서 해당 함수가 종료되면 스택 세그먼트에 올라왔던 변수들도 함께 소멸 된다. 데이터 세그먼트 프로그램이 빌드 되면서 올라오는 전역변수, STATIC 변수, 일반상수, 문자열 등이 쓰인다. 따라서 어느 함수에서나 호출이 가능하다. 데이터 세그먼트에서 호출된 변수들은 프로그램이 시작과 함께 선언되며 프로그램이 종료될 때 소멸 된다. 호출되는 함수와 함께 시작하고 소멸되는 스택 세그먼트의 변수와 상반되는 개념이다. 힙 세그먼트 메모리의 동적 할당 으로 표시되어 있다 정적으로 밖에 할당되지 않는 변수들을 개발자가 필요한 만큼 동적으로 할당하여 사용할 수 있는 메로리 출처 https://luckyyowu.tistory.com/6 http://blog.na...